![]()
Home Week-2
Java - Week 1
Java - Week 1Programming concepts:Programming languagesProgramming language:Compiler:InterpreterProgramming styles Imperative programming: Declarative Programming: The role of typesMemory managementActivation RecordHeap memory Abstraction and ModularityStepwise refinementData refinementModular software developmentProgramming language support for abstractionObject-oriented programmingObjectInheritanceSubtypingInheritance vs SubtypingDynamic lookupClassesExample: 2D points Adding methods to a classChanging the internal implementationAbstraction:Subtyping and inheritance
Programming concepts:
Programming languages
Programming language:
Programming languages are used to convey computational ideas to a machine that can execute them. Machine language is the only programming language that the machine can understand directly. Machine language instructions are binary coded and low level machine instructions may transfer the contents of one memory location to a CPU register or add numbers in two registers. So, let's take two registers R1 and R2. Add the contents of these two registers and store the result back in R1. Then you would take the contents of a register R1 put it back in memory. So, that you can free up the register for later work and also ensures the data is stored in memory. if you do not put it back in the memory the value is lost when the computer is switched off. So, this is obviously a very tedious and error prone way to program.
High level Programming languages were developed to enable programmers to write programs faster than low level machine language. A programming language is intended for mathematical computation, allows programmers to express numerical equations directly as:
X = (Y + Z) / 2
Since programs written in a high-level programming language are not recognized by the machine directly, we must use a compiler or interpreter to translate them to machine understandable language.
Compiler:
A compiler translates the entire program into machine language in a single run.
Compiler is faster than an interpreter because it takes the entire program during translation.
Compiler generates the intermediate code so it requires more memory than interpreter.
Interpreter
An interpreter translates the entire program into machine language line by line.
Interpreter is slower than an compiler because it translates the program line by line.
Interpreter never generates the intermediate code so it requires less memory than compiler.
Programming styles
There are mainly two types of programming styles: Imperative and Declarative programming.
Imperative programming:
An imperative programming tells the computer exactly how to do something?
In imperative style, we tell how exactly we want to achieve the result.
In imperative style use intermediate variables.
Example:
xxxxxxxxxxdef factorial(n): f = 1 while n > 0: f = f * n n = n - 1 return fprint(factorial(5))Declarative Programming:
A declarative programming means tells the computer what would we like to do and leave the part of how to do it.
In declarative style we actually say what results we want to get or what exactly we want to do.
In declarative style does not use intermediate variables.
Example:
xdef factorial(n): if n == 1 or n == 0: return 1 else: return (n * factorial(n - 1))print(factorial(5))
The role of types
A variable is a memory location to store a value, and every variable has a type. How is the variable type determined in Java and Python?
Python uses dynamic typing for variables where variable type is determined by assigning a value to it. During runtime variable value decides its type.
Example:
xxxxxxxxxxx = 10 # x is of type intx = 7.5 # now x is of type floatIf you determine the type in advance then it is called static typing. Java associates a type in advance with every variable name. Any type of mismatch errors must be caught by the compiler during compilation.
Example:
xxxxxxxxxxint x, float a;x = 7.5; y = 6.57 In the above statements, two variables are declared and variable x is initialized with incompatible value.
In Java, any type of errors is caught early by the compiler. If you try to assign an incompatible value to a variable, the compiler will identify it and throw an error.
Memory management
Whenever a function is invoked for execution, function needs memory for local variables, these local variables are used to store the intermediate results.
Activation Record
An activation record is a block of memory associated with an invocation of a function.
An activation record is pushed into the stack when a function is called and it is popped out when the control returns to the caller function.
Consider an example given below Example:
xxxxxxxxxxdef factorial(n): if n == 1 or n == 0: return 1 else: return (n * factorial(n - 1))print(factorial(3))
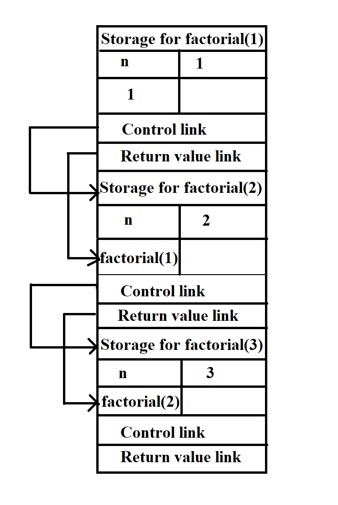
Whenever factorial(3) is called one activation is record is inserted into the stack memory, every activation record has memory for local variables, control link and return value link.
Control linkspoints to theprevious activation record.Return value linktells where to store the result.
In above image factorial(3) calls factorial(2) and factorial(2) calls factorial(1) so that two more activation records will be inserted in stack memory as shown in the figure.
Here factorial(2) control link points to the factorial(3) and factorial(2) control link points to the factorial(1).
Here factorial(2) return value will be stored in factorial(3), and the factorial(1) return value will be stored in factorial(2).
Heap memory
Heap memory is used for the dynamic memory allocation in Java at the time of execution (runtime). Whenever new objects are created, memory would be allocated in the heap memory. For example LinkedList uses dynamic memory allocation, it requires memory for new nodes as needed. LinkedList is implemented in heap memory because it's size is not fixed and can grow and shrink as needed whenever a node is inserted or deleted.
Unlike stack memory, allocations in heap memory are not free-up automatically. Java Virtual Machine uses a mechanism called Garbage collection to free-up the heap memory allocations. It identifies the objects which are not being used anymore by the Java program in execution and frees up the unused memory so other new objects can use that piece of memory.
In other programming languages like C and C++, programmer has to take care of freeing the memory allocated to unused objects. As a result it consumes the programmer time and increases the code complexity.
Abstraction and Modularity
Stepwise refinement
Consider the problem of computing and printing the first 1000 prime numbers. How this task can be achieved? To achieve this task we can develop a program by first outlining the major tasks that it should perform and then successively refining these tasks into smaller subtasks, until a level is reached at which each remaining task can be expressed easily by basic operations. This produces subproblems that are small enough to be understood and separate enough to be solved independently. See the first version of this program.
xxxxxxxxxxbeginprint first thousand prime numbersend
The above task can now be divided into subtasks. To divide the problem in two, some data structure must be selected for passing the result of the first subtask to the second. Here the data structure is a table, which will be filled with the first 1000 prime numbers.
See the second version of this program.
xxxxxxxxxxbegindeclare table pfill table p with first thousand primesprint table pend
In the next version each subtask are further elaborated. Here each subtask is considered independently, the problem of filling the table with primes is independent of the problem of printing the table. Therefore, each subtask can be assigned to a different programmer, allowing the problems to be solved at the same time by different people. See the final version of this program.
xxxxxxxxxxbegininteger array p[1:1000]for k from 1 through 1000make p[k] equal to the kth prime numberfor k from 1 through 1000print p[k]end
Data refinement
In addition to dividing the tasks into simpler and manageable subtasks, evolution in a system design may lead to changes in the data structures that are used to combine the actions of independent modules.
Consider developing a simple banking program. The main goal of this program is to create a new account, deposit an amount, withdraw an amount, and print monthly/quarterly bank statements. In the first version of this program, we might formulate a system design that has the following functions:
CreateAccount(), Deposit()/Withdraw(), PrintStatement()
In this program development, the main function receives a list of input transactions and calls the appropriate functions. Assume that statements only contain the account number and balance, then we can represent a single bank account by an integer value and store all bank accounts in a single integer array.
Later refine the task Print Statement() to include the subtask "Print the transactions list," then we will have to maintain a record of bank transactions. For this refinement, we will have to replace the integer array with some other data structure that records the sequence of transactions that have occurred since the last statement. This may require changes in the behavior of all the subtasks, as all of them perform operations on bank accounts.
Modular software development
Divide and conquer is one of the fundamental technique. It is important to divide large and complex programs into smaller and manageable parts called functions or procedures, that can be solved independently. Use refinement to divide the program into functions or procedures. These functions or procedures called to generate the solutions. The solutions generated by these functions are combined to provide the overall solution for the main program.
Prototyping is a development method, involves implementing smaller parts of a program in a simple way to understand if the design will really work. Then, after the design has been tested in some way, one can improve parts of the program independently by reimplementing them.
There are two important concepts in modular program development: interfaces and specifications.
Interface: It is a description of the parts of a component that are visible to other program components.Specification: It is a description of the behavior of a component, as observable through its interface.
Programming language support for abstraction
In programming languages, an abstraction is an important object oriented principle that separates a implementation of program from it's interface.
Control abstraction
In earlier days of programming, abstractions are implemented using the procedures or functions.
procedures or functions are used encapsulate the block of code, and the implementation of a function is the function body, which consists of the instructions that will be executed whenever function is being invoked.
Data abstraction
Data abstraction is refers to the hiding information about the way data is represented.
Abstract datatype
Abstract datatype exposes what the operations that are performed on the data structure and what are the values permitted to store in the data structure rather than how it is implemented. Here the operations and values permitted on the data structure are visible to the other parts of a program using a public interface .
There are three main goals of abstraction:
Identify the interface of the data structure. The interface of a data abstraction contains the operations permitted on the data structure, and their arguments and return result.
Provides information hiding by separating implementation decisions from parts of the program that use the data structure through an interface.
Allows the data structure to be used in many different ways by many other programs.
Example Stack is a linear data structure. If it is implemented using an array, then programs that use a stack abstract data type can see and use only the operations performed on the stack (push() and pop()), not array operations such as indexing into the array at arbitrary points. This hides information about the implementation of a data structure and allows the implementer of the data structure to make changes without affecting parts of the programs that use the data structure.
Object-oriented programming
There are few basic concepts of object-oriented programming (OOP).
Object
Object are like abstract datatypes. Every object has its own data (also called state) and operations (also called methods/messages). A program written in object-oriented style will consist of interacting objects. For example, a Student object may consist of data such as name, gender, birth date, home address, phone, and age, and operations for assigning and changing these data values.
Inheritance
Inheritance is the process by which one object re-use the implementations of another object. For example if you consider an organization that has two types of employee namely Employee and Manager. A Manager is also an Employee but every Employee is not a Manager.
Here Employee class has functionality like basic personal data, date of joining. This same data also required for a Manager class, using inheritance we can use the functionality of Employee in the Manager class. You can also add extra functionality to the Manager like date of promotion, seniority (in current role) if required .
Subtyping
A subtype is a specialization of a type, If A is a subtype of B, wherever an object of type B is needed, an object of type A can be used. Every object of type A is also an object of type B. If f() is a method in B and A is a subtype of B, every object of A also supports f().
Consider the code given below:
xxxxxxxxxxclass Employee:def __init__(self,n='',s=0.0):`self.name = nself.salary = sdef bonus(self):return(0.1*self.salary)`class Manager(Employee):def __init__(self,n='',s=0.0):self.name = nself.salary = sdef bonus(self):return(0.2*self.salary)`
Here Manager is a subtype of an Employee. Wherever an object of Employee (super type) is required, an object of Managercan be used.
If bonus() is a function in Employee and Manager is a subtype of Employee, every object of Manager also supports bonus(). Implementation of bonus() can be different in Manager.
Inheritance vs Subtyping
In object-oriented programming, inheritance and subtyping both are essential.
Subtyping refers to compatibility of interfaces. A type
Ais a subtype ofB, wherever an object of typeBis needed, an object of typeAcan be used.Inheritance refers to reuse of implementations. If a type
Ainherits from another typeB, thenAcan reuse the functionality ofBwithout redefining it, and typeAcan also add more features to it if required.
Consider the data structure deque, a double-ended queue. A deque supports insertion and deletion at both ends, so it has four functions insert-front, delete-front, insert-rear and delete-rear. If we use just insert-rear and delete-front we get a normal queue. On the other hand, if we use just insert-front and delete-front, we get a stack. In other words, we can implement queues and stacks in terms of deques, so as datatypes, Stack and Queue inherit from Deque. On the other hand, neither Stack nor Queue are subtypes of Deque since they do not support all the functions provided by Deque. In fact, in this case, Deque is a subtype of both Stack and Queue
Dynamic lookup
Dynamic lookup means that a method to be invoked at run time, according to the implementation of the object that receives a message. The important property of dynamic lookup is that different objects may implement the same method differently.
Dynamic lookup is an important part of object-oriented programming. Consider, for example, a simple graphics application that draws the shapes such as squares, circles, and triangles. Each square object may contain a draw method with code to draw a square, each circle a draw method that contains code to draw a circle, and so on. When the program wants to draw a given shape, sending a draw message to each shape. The part of the program that sends the draw message does not have to know which kind of shape will receive the message. Instead, each shape receiving a draw message will know how to draw that shape. This makes sense because the programmer who implements a specific shape knows how to draw that kind of shape.
Classes
A class is a template that describes what objects can and cannot do. An object is an instance of a class. Class describes how data is stored in objects and how the public functions/methods manipulate this data.
Example: 2D points
To understand the basic ideas and limitations of the Python language, consider the following example program in Python.
xxxxxxxxxxclass Point: def __init__(self,a=0,b=0): self.x = a self.y = bIn the above example, the class Point is defined. Each instance of the Point class has its own instance variables x and y. These instance variables store the x coordinate and y coordinate of a point in a 2D space, allowing us to identify the location of a point in 2D space.
For example, if p1 and p2 are two instances of the Point class, then the instance variables associated with p1 and p2 are denoted as p1.x, p1.y, p2.x, and p2.y.
Adding methods to a class
We can manipulate the object's internal data by adding functions in the class. For example, if we want to shift a point by a certain amount given by
After shifting, the point becomes (
You can also calculate the distance from the origin using the formula:
d =
xxxxxxxxxxclass Point: def __init__(self,a=0,b=0): self.x = a self.y = b def translate(self,dx,dy): self.x += dx self.y += dy def odistance(self): import math d = math.sqrt(self.x*self.x + self.y*self.y) return(d)Changing the internal implementation
Now let's see how to represent a point in terms of distance
xxxxxxxxxximport mathclass Point: def __init__(self,a=0,b=0): self.r = math.sqrt(a*a + b*b) if a == 0: self.theta = math.pi/2 else: self.theta = math.atan(b/a) def odistance(self): return(self.r)In above program we are passing
To translate the polar coordinates to Cartesian coordinates, we can convert (
Now recompute the polar coordinates (
xxxxxxxxxxdef translate(self,dx,dy): x = self.r*math.cos(self.theta) y = self.r*math.sin(self.theta) x += dx y += dy self.r = math.sqrt(x*x + y*y) if x == 0: self.theta = math.pi/2 else: self.theta = math.atan(y/x)We can use the same constructor definition to set both the cartesian coordinates (
Abstraction:
The purpose of abstraction is to hide the implementation details from the user. In the case of the Point class, the user should not be concerned about whether it represents cartesian coordinates (Point object using a consistent interface, regardless of how the data is actually stored internally.
xxxxxxxxxxclass Point: def __init__(self,a=0,b=0): self.x = a self.y = bIn above program point representation is (
xxxxxxxxxxclass Point: def __init__(self,a=0,b=0): self.r = math.sqrt(a*a + b*b) if a == 0: self.theta = math.pi/2 else: self.theta = math.atan(b/a)In above program point representation is (
In Python, direct access to instance variables from outside the class is allowed, which means that abstraction is not enforced in the language.
xxxxxxxxxxp = Point(5,7)p.x = 4 # Point is now (4,7)In the above code, during object creation, the arguments (5, 7) are passed to the constructor. However, the statement p.x = 4 changes the value of x to 4, resulting in a new state of the object as (4, 7). According to the concept of abstraction, this should not happen, as it violates the idea of encapsulation and can have an impact on other parts of the code. In Python, abstraction is highly dependent on the discipline of the programmer to respect the encapsulation and not access or modify the internal implementation details directly.
Subtyping and inheritance
Let's explore the concept of subtyping and inheritance in the context of Python.
xxxxxxxxxxclass Rectangle: def __init__(self,w=0,h=0): self.width = w self.height = h def area(self): return(self.width*self.height) def perimeter(self): return(2*(self.width+self.height))class Square(Rectangle): def __init__(self,s=0): self.width = s self.height = sIn above example Rectangle has two dimensions a width and height. We have a constructor for Rectangle to initialize the internal instance variables self.width and self.height. And has two public functions area and perimeter.
Now one more class Square is defined, a square is a rectangle in which the width is equal to the height. So, we can now define a Square to be a sub type of Rectangle. In Python we do this is that in the class definition of square put the type Rectangle in the bracket.
Here Square is a specialization of a Rectangle and here we can define a new constructor because Square have one quantity that is side it do not have a width and a height and will reset the width and the height both using side value. The constructor of Square that we have defined here is different from Rectangle there because there we got two parameters and we set them but here we get only one parameter.
xxxxxxxxxxs = Square(5)a = s.area()p = s.perimeter()In above I want a Square with side 5 this will create implicitly an object which has width and height values as 5. After that now calling s.area() for the area of the square, will return a legitimate value of 25 even though inside this there is no area function here. This is the idea of inheritance. Square is a sub type of Rectangle the functions which are defined inside Rectangle are available to Square. So, we do not have to redefine them unless we want to change them. So, perimeter and area are both inherited by Square from Rectangle.
xxxxxxxxxxclass Rectangle: def __init__(self,w=0,h=0): self.width = w self.height = h def area(self): return(self.width*self.height) def perimeter(self): return(2*(self.width+self.height))class Square(Rectangle): def __init__(self,s=0): self.side = sNow suppose if I decided that in a Square I do not want to keep track of two separate variables there is only one variable that is side. Now if we try the same code which earlier work due to inheritance. These two functions will now at run time they will fail.
Statically these functions are available because Square has been defined to be a subtype of Rectangle. So, those functions are available to Square. So, if they are not defined in Square and if I say s.area() Python has no way to know before running the code that this s.area() will not work. But when it actually comes to executing s.area() it will check that these quantities self.width() and self.height().
Here Square constructor changing the instance variable self.side but we did not update self.width or self.height explicitly. Since we did not update them they become undefined variables. So perimeter and area are used for their calculations because self s.width and s.height have not been defined.
The subtype Squareis not forced be an extension of the parent type. The subtype can do everything the parent type will do and more and in particular that means that it should have all the instance variables that the parent type would have declared and more because the functions would use these instance variables. But here in Python we are able to do this, we can set up instance variables in the subtype and omit some instance variables from the parent type. So, this is clearly not a good thing.